
Data Quality: framework di riferimento
Nel mondo dell’analisi dati e dell’Intelligenza Artificiale, uno dei temi più rilevanti, seppur talvolta sottovalutati, è quello della qualità dei dati, qualunque siano la tipologia e lo scopo dell’analisi.
Il motto “Garbage in – Garbage out” per cui se i dati sono errati o privi di significato, anche i risultati dell’analisi lo saranno, rimane sempre valido e fondamentale.
Articolo a cura di Laura Rocchi, Area Ricerca e Innovazione, NIER Ingegneria
ACCURATEZZA DEI DATI E SOLIDE “FONDAMENTA”
Prima di applicare efficacemente algoritmi di Artificial Intelligence (AI) o Machine Learning (ML), occorre che il processo a monte posi su solide fondamenta, come rappresentato dallo schema piramidale di Figura 1 (ispirata a [1]).
Si tratta quindi di partire assicurandosi l’accuratezza dei dati grezzi (raw data), che possono provenire da una varietà di fonti (ad es. sensori, social network, ERP…), in vari formati e in grandi quantità. Le fasi di Data Engineering e Management stabiliscono il contesto e la struttura necessari affinché i dati possano divenire informazioni, così come la loro gestione, e possa esserne garantita la qualità prima di passare alle ultime fasi di analisi. La fase di Analisi può essere divisa in due macro aree: 1) Reporting e Business Intelligence/Visualization che rappresentano l’inizio della raccolta di informazioni approfondite, in cui queste vengono aggregate, suddivise per facilitare le analisi successive.
Le valutazioni sono tipicamente basate su visualizzazioni di dati aggregati in diverso modo, al fine di effettuare un primo screening, valutare prime correlazioni e trend, identificare possibili dati e informazioni mancanti, ridefinire lo scopo dello studio, progettare i passi successivi di analisi e ed eventualmente progettare possibili altre acquisizioni dati.
Sono analisi queste dove le “competenze di dominio” sono fondamentali; 2) Data Science, dove è possibile sviluppare modelli più approfonditi e data-driven, sia in termini di AI, ML o modellazioni statistiche sui processi sotto osservazione.
Ci si avvale delle conoscenze già sviluppate nella fase precedente, potendo però identificare pattern e relazioni multivariate e “nascoste” ai soli strumenti di analytics della fase precedente.
Questa schematizzazione “a piramide” evidenzia che è necessario porre attenzione alle fasi alla base della piramide, che costituiscono appunto le fondamenta dell’intero processo, al fine anche di evitare eccessivi sforzi, ad esempio, nell’ottimizzazione di algoritmi e nell’invenzione di metodi di reporting e automazione nella gestione dei dati, quando potrebbero essere proprio i dati grezzi, all’origine, caratterizzati da scarsa affidabilità.

AFFIDABILITÀ DEI DATI E PROCESSI DI ACQUISIZIONE
Un altro framework di lavoro sui dati che presentiamo prende spunto da un recentissimo articolo, pubblicato su Frontiers in Artificial Intelligence nel Giugno 2021 [2], in cui si ribadisce la rilevanza del Cross-Industry Standard Process for Data Mining (CRISP-DM), schematizzato nella Figura 2 e che riguarda la qualità dei dati nei contesti industriali.
La Figura 2 è estratta dall’articolo citato [2] e rimarca la relazione bidirezionale fra le diverse fasi proposte, evidenziando come il processo di acquisizione dei dati sia ricorsivo e in continua evoluzione.
In particolare lo schema evidenzia come la fase di modellazione (Modelling) dipenda dalla preparazione dei dati (Data Preparation) e viceversa: infatti quando la preparazione dei dati è completa, si può implementare un modello di AI, che richiede alcuni requisiti dei dati. Affinché i requisiti necessari siano soddisfatti potrebbe esserci l’evenienza di tornare alla Data Preparation e applicare vari metodi di pre-elaborazione. Analogamente, a titolo di esempio, le fasi di acquisizione e preelaborazione/comprensione dei dati (Data preparation/understanding) possono essere confermate o integrate man mano che si sviluppano gli obiettivi dell’analisi dei dati ed eventualmente si può concordare che sia necessario progettare degli esperimenti specifici o acquisire nuovi dati durante l’attività della strumentazione o del processo sotto osservazione.
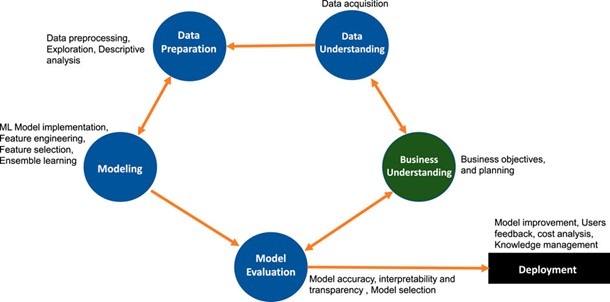
Le fasi di Data Preparation, Data understanding e in parte Modelling richiedono, a nostro giudizio, una forte competenza del problema specifico che si sta analizzando, sia questo di tipo fisico/sperimentale (se si ci si sta occupando di una macchina o strumentazione), di processo o in generale del fenomeno sotto osservazione che genera i dati.
L’ultimo aspetto che trattiamo entra nel merito della definizione specifica di Data Quality e in particolare della loro affidabilità.
Un lavoro pubblicato nel 2015 su Data Science Journal [3], ha schematizzato le caratteristiche base per la qualità dei dati, che condividiamo e proponiamo, seppur con alcune modifiche e integrazioni basate sulla nostra esperienza.
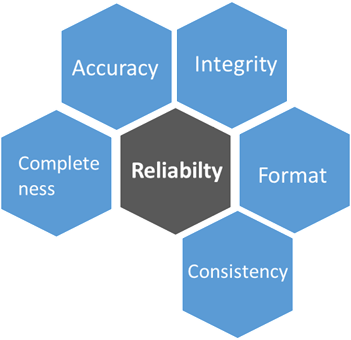
In un framework ampio di Data Quality che include anche aspetti quale la disponibilità e la qualità nella rappresentazione dei dati, poniamo particolare attenzione al tema della Data Reliability (Affidabilità dei dati), costituito dai fattori rappresentati qui sotto descritti:
- Accuracy (Accuratezza) della misura del dato: ovvero il dato e il suo valore rappresentano il valore vero; il dato non è ambiguo.
- Integrity: il contenuto e il formato dei dati è integro.
- Consistency: consistenza dei dati, dopo il processing essi continuano ad avere lo stesso concetto e dominio dei dati originali; il dato è reperibile e verificabile all’interno di un intervallo di tempo, così come la sorgente dei dati.
- Completness: riguarda l’impatto di possibili mancanze di un componente del sistema sulla generazione o affidabilità dei dati. E’ un concetto che richiama temi come la ridondanza nell’acquisizione dei dati o il monitoraggio delle sorgenti dei dati.
- Format: riguarda il formato dei dati, in particolare del loro contenuto. Ad esempio si possono correre dei rischi di sviluppare analisi con dati non aggiornati correttamente, o di subire variazioni di formato o di unità di misura senza corretta informazione.
CONCLUSIONI
L’esperienza, insieme alla complessità dei temi quando si tratta di trarre conoscenza dai dati, ci portano a sottolineare l’importanza dell’approccio multidisciplinare ai temi dell’analisi dati.
L’intero processo deve essere governato per non incorrere nel rischio del garbage in – garbage out e per non illudersi che modelli per quanto sofisticati possano trovare informazioni laddove non presenti, o danneggiate o non correttamente gestite.
La conoscenza specifica sul fenomeno che i dati descrivono è l’aspetto più rilevante che può sovraintendere il processo, in modo da basare le analisi su solide fondamenta, avere chiarezza dell’interconnessione fra le diverse fasi di generazione della conoscenza, essere consapevoli dei temi cruciali che costituiscono l’affidabilità dei dati.
Questo articolo è inerente il progetto “KINEMA” cofinanziato dal consorzio BI-REX nell’ambito del Programma Competence Centre del Ministero dello Sviluppo Economico. I contenuti, le opinioni e i dati inclusi sono quelli degli autori.
Bibliografia:
[1] https://sensecorp.com/data-science-pyramid/
[2] Thripathi S. et al., “Ensuring the Robustness and Reliability of Data-Driven Knowledge Discovery Models in Production and Manufacturing”, Front. Artif. Intell., 14 June 2021
[3] Cai L. and Zhu Y. “The Challenges of Data Quality and Data Quality Assessment in the Big Data Era”, Data Science Journal 2015, 14: 2, pp. 1-10
[4] Data Quality — A Primer, Memory Link – Medium
• Siamo felici di accogliere queste nuove sfide insieme e di potervi supportare nella definizione e implementazione di una strategia di Analisi dei Dati: scrivici a BD@nier.it